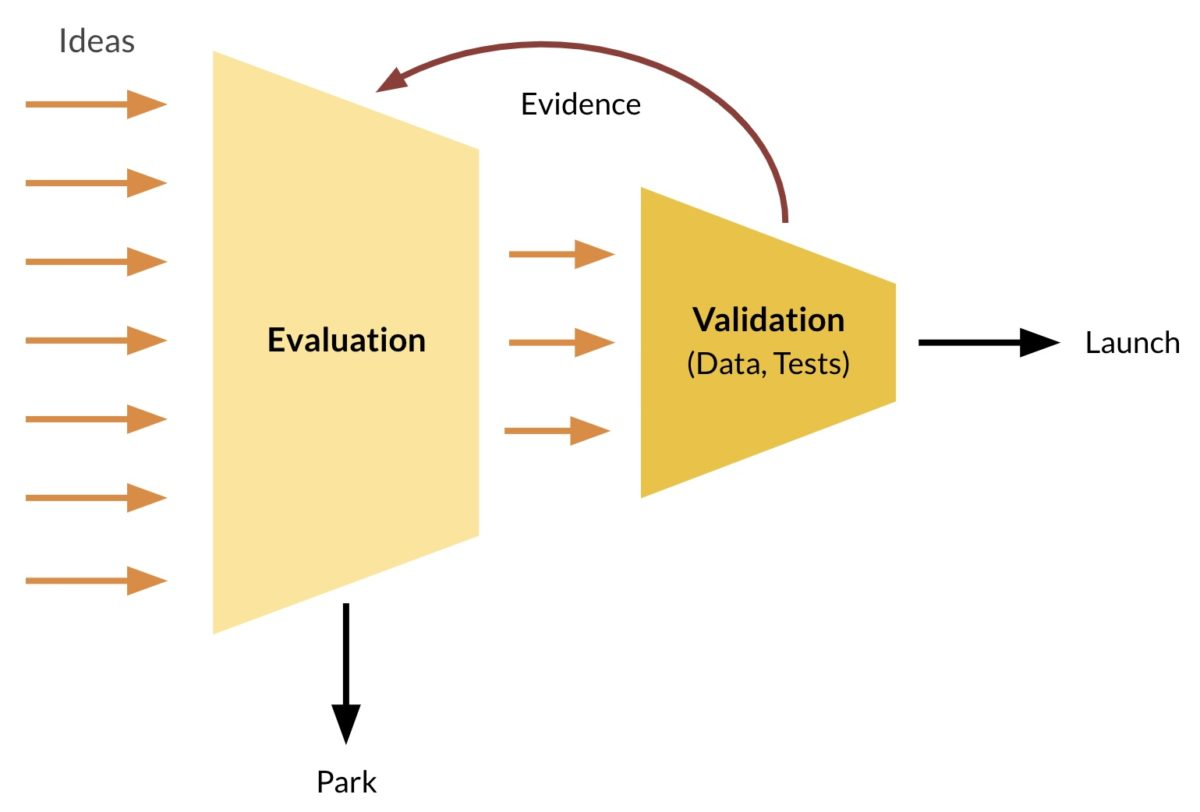
It’s ok to release minor tweaks based on assessment
Having supporting data (without testing) is enough to launch only very small, low-risk, easy-to-revert changes
Everything else should be validated through tests and experiments.
How much validation you need depends on: a) the cost of building the idea in full, b)how risky it is, c) your risk tolerance.
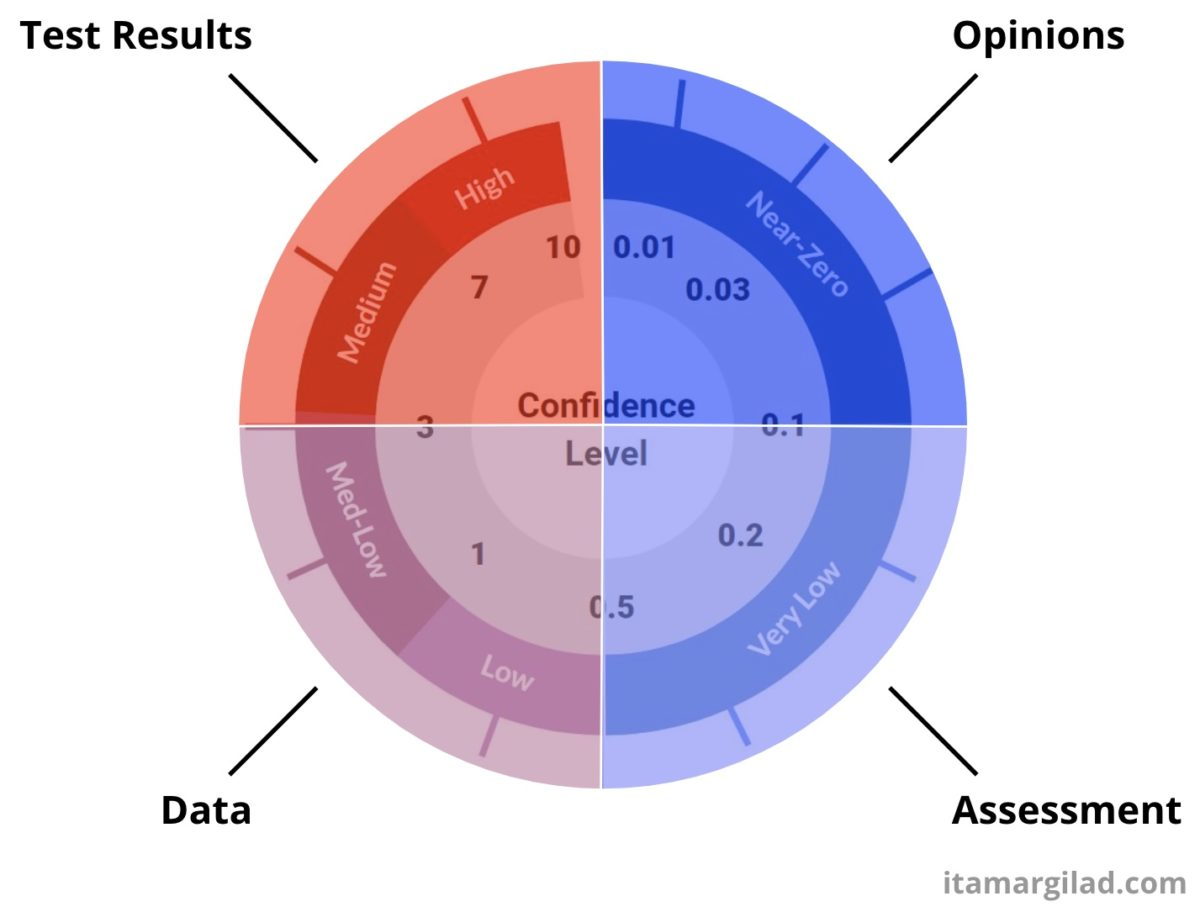
Opinions (Confidence <0.1)
This form of evidence is based on the self conviction of a single person or a small group of like-minded people (who aren’t the intended user).
Assessment (0.1 < Confidence Level ≦ 0.5)
Projections and business models — Using back-of the envelope calculations, business model canvas, and other forms of business/tech analysis to refine our estimates of impact and ease.
Risk analysis — For example through assumption mapping (for reference consider Cagan’s Four Big Risks)
Reviews — Including peer reviews, expert reviews, management reviews, and stakeholder reviews.
Data (0.5 > Confidence Level <=3)
Data Sources
Customer/user requests
Customer/user interviews
Field studies
Log and usage data
Competitive research
Market research
Surveys
Other sources
Anecdotal data (Confidence Level of 1.0 or less) comes from a small set of data points: 1-3 users/customers expressing
Anecdotal data shows that at least someone outside the building
We should use anecdotal evidence to OK just very low-effort, very low-risk ideas.
Market data (Confidence Level between 1.0 and 3.0) comes from larger datasets.
13 out of 20 potential customers we interviewed rated HDR-support as very important in their choice of video platform
68% of consumer devices support HDR video
3 out of 11 competitors have HDR support
4 more have it on their roadmap
but if we don’t have the capacity, these are examples of ideas where it might be ok to take the risk:
Incremental features that add new functionality (rather than change or subtract), and are unlikely to annoy anyone, for example HDR support
Redesigns of parts of the UI that users don’t visit often — e.g. the settings page
Short-duration, in-product promos and calls-to-action
We definitely don’t want to bloat the product with features no one uses.
Tests and Experiments (3 < Confidence Level)
Testing means putting a version of the idea in front of users/customers and measuring the reactions.
Early-stage tests use a “fake product” or a prototype before the product is built, for example landing pages, wizards of Oz, concierge services, and prototype usability studies.
Mid-stage tests, for example internal team dogfood, early adopter programs, alpha, real product-based usability tests, use a rough and incomplete version of the idea with a small group of users.
Late-stage tests (e.g. betas, labs, previews) use an almost-complete version of the idea with a larger group of users
Split tests (e.g. a/b, multivariate) test complete versions of the idea with lots of users, and include a control element to reduce the odds of false results.
Launch tests use partial roll-outs to test the finished idea on a large scale.
questions about value in use, usability, and adoption and usage patterns. These are more expensive tests, and they’re enough to greenlight most medium risk and/or medium cost ideas.
a new core feature, removing or replacing an existing feature, a major redesign, minor new product.
when the idea is going to affect all/most users in a big way
and you want to ensure it’s bullet-proof, or 2) when some assumptions
can only be validated with large amounts of data.
use them for cases where you need quantitative data to validate the assumptions,
Will people choose this option? Will we earn more money?
Will retention not degrade?
At a minimum we’d like to ensure that our most critical assumptions, the ones that may make the idea useless, are validated.
We start with cheaper modes of validation (assessment, data gathering, early-stage tests), and move to more expensive ones only if the idea still looks good.
Every time we collect new evidence we should reevaluate the idea and decide what to do next.